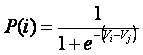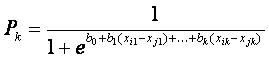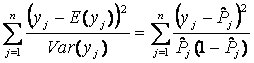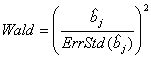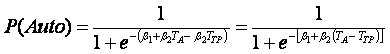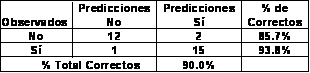|
||||||||||||
Introducción La planeación del transporte frecuentemente encuentra situaciones donde los usuarios del servicio deciden entre alternativas. Por ejemplo, se va al trabajo optando entre automóvil propio o transporte público, se viaja a otra ciudad escogiendo entre autobús o avión, o se envía carga ya sea por camión o por ferrocarril. El planificador del sistema de transporte se interesa en el modo en que los usuarios eligen las alternativas, a fin de influir en las decisiones y así racionalizar el uso de recursos. Las campañas para reducir el uso del automóvil a favor del uso de transporte público o para transferir carga del autotransporte hacia el ferrocarril son dos ejemplos de esto. En esta tarea de planeación, el modelado de las elecciones de los usuarios resulta de gran utilidad. Este artículo presenta una síntesis básica de uno de los modelos de elección entre alternativas que se usa ampliamente en el campo del transporte: el modelo Logit. Se muestra también un ejemplo numérico típico para este modelo. El modelado de la elección de alternativas Para entender las acciones del usuario, el modelador muestrea las distintas situaciones que ocurren. Por ejemplo, para distintas combinaciones de costo y de tiempo de viaje, digamos en autobús y en automóvil, se observan las elecciones de los pasajeros. Basado en los datos de la muestra el modelador busca una regresión, esto es, una función o una curva que se ajuste a los datos lo mejor posible a fin de poder estimar situaciones que aún no se han observado. El modelado se inicia suponiendo que los atributos tanto del usuario (su edad, el motivo de viaje, etc) como de las alternativas (costo, tiempo de viaje, comodidad, etc), influyen en la decisión. Admitiendo que el usuario es racional, la guía de su decisión es la utilidad que le ofrece cada alternativa. Un enfoque común es suponer que esta utilidad es función lineal de los atributos implicados en la decisión. Así, por ejemplo, al elegir entre automóvil o transporte público, la utilidad Vj de la alternativa “j” es una función lineal de los k atributos x1, x2, …, xk que se presume influyen en la decisión (ingreso del usuario, edad, costo del viaje, tiempo de viaje, etc) como sigue:
En el mundo real sin embargo, individuos aparentemente semejantes (estudiantes, oficinistas, amas de casa, etc) escogen de
donde Vj es llamada la utilidad sistemática y εj es un error aleatorio que permite modelar gustos de los usuarios, factores de su personalidad, errores de medición o factores que el modelador no puede observar (Ortúzar, 2000). La racionalidad del usuario lo lleva a maximizar su utilidad, así que éste optará por la alternativa “i” siempre que Uj £ Ui, con lo que la probabilidad Pr(i) de que elija la alternativa “i” es:
Para hacer manejable la expresión anterior, se necesitan hipótesis sobre la distribución de probabilidad conjunta de los errores εk. La primera hipótesis es considerarlos independientes e idénticamente distribuidos (IID) y la segunda se refiere a la forma de su distribución de probabilidad. Distintas formas para la distribución de probabilidad de las diferencias εj.- εi generan distintos modelos, p ej de Probabilidad Lineal al suponer una distribución uniforme o Probit si se supone una distribución normal. En el modelo Logit, se supone que los errores εk tienen una distribución Gumbel (también llamada de valores extremos), por lo que las diferencias εj - εi resultan tener una distribución Logística (Ben-Akiva & Lerman, 1985, p. 71). El último término en las ecuaciones (2) es la función de distribución acumulada (FDA) de las diferencias εj - εi, de modo que la probabilidad de elegir la alternativa “i” en el modelo Logit viene dada por:
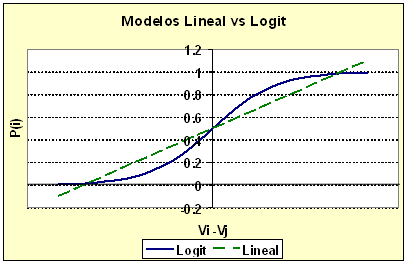
La gráfica de P(i) contra la diferencia Vi - Vj en la ecuación (3) es una curva alargada en forma de “S” similar a las curvas de reparto de pasajeros entre modos de transporte (p ej usuarios de automóvil y de transporte público) obtenidas empíricamente en los primeros estudios de transporte urbano para estimar las proporciones de pasajeros que escogerían cada modo según la diferencia entre el costo de las opciones (Ortúzar & Willumsen, 1990). Los modelos Logit realmente son una familia de modelos de elección discreta; de los más conocidos están los siguientes. Cuando sólo hay dos elecciones posibles, se tiene un modelo Logit Binario; si hay más de dos opciones, se tiene el modelo Logit Multinomial; y si existen semejanzas en algunas opciones que se puedan “anidar” dentro de una clasificación común (P ej autobús urbano y taxi colectivo como opciones de “transporte público”) se tiene un modelo Logit Anidado. (Ortúzar & Willumsen, 1990). El contexto estadístico del modelo: ¿por qué no usar un modelo lineal? Al modelar la elección de alternativas podría preguntarse si no es más sencillo aplicar un modelo de regresión lineal ajustado por mínimos cuadrados ordinarios (MCO) en vez de usar el modelo Logit descrito. Hay razones por las que esto no es adecuado. Para empezar, una elección puede ser un “Sí” (asociado típicamente al valor “1”) o un “No” (asociado al valor “0”), o también puede ser la proporción de usuarios eligiendo una opción (p ej “Sí” al uso de automóvil). El modelo lineal, al ser una función continua de las variables explicativas, no acota la respuesta entre 0 y 1, ya sea ésta discreta (0 ó 1) o sea la proporción de usuarios eligiendo una opción. La Figura 1 ilustra el distinto comportamiento de los modelos lineal y Logit. Adicionalmente el supuesto de varianza constante del modelo lineal de MCO para las respuestas de este tipo no se cumple. Para ver esto, nótese que de la ecuación (3) P es la probabilidad de que un usuario elija la alternativa “i”, así que en una muestra de n observaciones, con respuestas y1, y2, …,yn, cada una correspondiendo a distintas variables de decisión de los n distintos usuarios, Pk = Pr( yk = 1) es la probabilidad de que la respuesta del usuario k sea “1”, resultando que cada yk representa una variable aleatoria Bernoulli con probabilidad de éxito Pk, y la siguiente función de densidad:
No es difícil verificar que la respuesta esperada y la varianza en cada observación k son las siguientes:
Figura 1. Comparación del Modelo Lineal y del Modelo Logit Ya que la varianza de yk cambia con la media Pk, la que a su vez depende de las variables independientes, no puede suponerse varianza constante entre las distintas observaciones. Este hecho invalida el supuesto de varianza constante en los errores requerido por el modelo lineal de MCO. El modelo Logit resuelve las limitaciones del modelo de regresión lineal al acotar la respuesta entre 0 y 1, además de que asigna consistentemente probabilidad de 0.5 cuando la diferencia entre utilidades sistemáticas Vi - Vj es cero , que es Estimación de los parámetros Para definir el modelo Logit hay que estimar los parámetros b0,…,bk incluidos en la expresión Vi - Vj de la ecuación (3). El método comúnmente usado es el de máxima verosimilitud (maximum likelihood estimation). Este método estima los parámetros desconocidos de la densidad de probabilidad asociada a la muestra de valores observados, buscando el valor numérico de los parámetros que maximizan la probabilidad de obtener justamente esa muestra. El proceso de estimación emplea la función de verosimilitud (likelihood function) L(b0,…,bk) que representa la probabilidad conjunta de haber obtenido la muestra y1, y2, …, yn, mediante el producto de las densidades de probabilidad asociadas a cada una de las observaciones yj. Los parámetros que maximizan esta probabilidad conjunta se obtienen con técnicas tradicionales de cálculo. En el modelo Logit la muestra y1, y2, …,yn, está formada por variables independientes Bernoulli cada una con probabilidad
donde, por la ecuación (3) Igualando a cero las derivadas parciales de L(b0,…,bk) respecto de cada uno de los parámetros bj se obtienen las llamadas ecuaciones “score”, que en general es un sistema de ecuaciones no lineales cuya solución son los valores Inferencia estadística Ya ajustado el modelo y previo a su uso, hay que evaluarlo y determinar qué tan bueno fue el ajuste, o sea, hay que medir el grado de bondad de ajuste. También debe verificarse que los parámetros estimados tengan sentido en la modelación, para lo cual se hacen ciertas pruebas de hipótesis. En el modelo de regresión lineal de MCO, las distribuciones de las estadísticas usadas en las pruebas de hipótesis resultan de la distribución normal de los errores y de su varianza constante; como el modelo Logit no tiene estos supuestos, las pruebas de hipótesis emplean otras estadísticas. Evaluación del ajuste en el modelo Logit Para evaluar el ajuste de un modelo Logit, no hay una medida tan clara como el coeficiente de determinación R2 usado en el caso de MCO, sin embargo hay varias propuestas de medidas de ajuste, la más común es la siguiente (Greene, 2000)
llamada R2 de McFadden o Pseudo R2, que análogamente a R2 está acotada Otra forma muy simple de evaluar un modelo Logit, es comparar los valores pronosticados de la respuesta con los valores observados en la muestra, usando una tabla llamada de clasificación, como se ve enseguida. Así mientras se obtengan un mayor número de predicciones correctas el modelo será mejor.
De modo más formal se puede evaluar el ajuste de un modelo Logit con una prueba de hipótesis, donde la hipótesis nula es que los datos observados provienen de una distribución logística con los parámetros estimados. Una de las estadísticas más usadas para esta prueba de hipótesis es la siguiente:
la cual tiene una distribución c2 con n - (k +1) grados de libertad donde Significancia de los parámetros del modelo En lenguaje estadístico significativo indica la capacidad de una variable independiente xj de contribuir a explicar la respuesta observada, y numéricamente esto equivale a pedir que el parámetro para esta variable, bj, sea estadísticamente distinto de cero. Para cristalizar la idea, se usan pruebas de significancia de los parámetros del modelo,
donde b0* es la estimación del parámetro b0 sin considerar los parámetros restantes (ya que bajo H0 se supone b1 = … = bk = 0) y L es la función de verosimilitud. Sin embargo esta prueba da poca información sobre el modelo pues si la hipótesis nula se rechaza, como frecuentemente sucede, esto sólo indicaría que el modelo explica mejor a los datos al considerar los factores correspondientes a los parámetros b1,…,bk que sin ellos, pero no indica cuáles de estos factores son importantes y cuáles pueden eliminarse sin afectar demasiado al modelo. Si la hipótesis global H0 : b1 = … = bk = 0 se rechaza, usualmente se prueba de manera individual
que bajo la hipótesis nula se distribuye asintóticamente como c2 con 1 grado de libertad. Finalmente, para decidir si se rechaza la hipótesis nula, primero se calcula la estadística de prueba obtenida con los datos observados, y luego se calcula qué tan probable es obtener este valor con base en la distribución de la estadística de prueba bajo la hipótesis H0. Generalmente se adopta el 5% de significancia, así que si la probabilidad de observar el valor obtenido es menor a 0.05 la hipótesis nula se rechaza. Muchos paquetes estadísticos dan esta probabilidad como la significancia de la prueba o valor p, así que mientras más pequeños sean estos valores mayor evidencia hay en contra de la hipótesis nula en favor de la alternativa. Un ejemplo numérico simple Supóngase que deseamos modelar la preferencia de uso de automóvil contra uso de transporte público a partir de una muestra de
donde TA y TTP son los respectivos tiempos de recorrido en auto y en transporte público. Entonces, por la ecuación (3), el modelo a ajustar es:
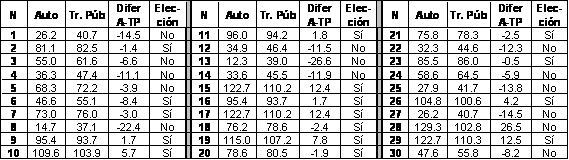
Los datos para el ejemplo se muestran en la siguiente tabla, generada por simulación con el supuesto de que β1 = 0.6153 y β2 = 0.1704. Las columnas “Auto” y “Tr. Púb.” son los minutos de recorrido en cada modo de transporte, la columna “Difer A – TP” es la diferencia del tiempo en auto menos el tiempo en transporte público, y la columna “Elección” indica la decisión del usuario en cada observación.
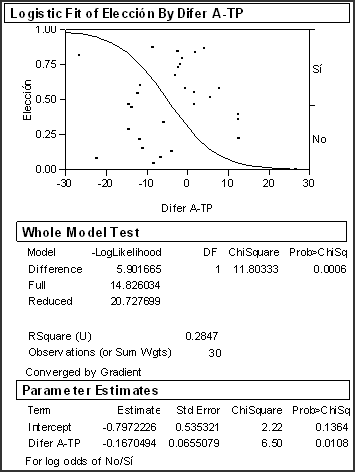
Se usó la rutina de regresión logística (Logistic) del menú de Estadística Básica (Basic Stats) del paquete JMP v.4.04 del SAS Institute Inc, ingresando la variable “Elección” como Respuesta Categórica ( Categorical Response) y la variable “Difer A -TP” como Regresor Continuo (Continuous Regressor).Los resultados del paquete estadístico se muestran en la Figura 2. La curva logística en la sección “Logistic Fit” muestra cómo a medida que la diferencia de tiempo Auto contra Transporte Público se reduce (o sea mejores tiempos en auto) la probabilidad de elegir auto se acerca a 1. En la sección de prueba del modelo completo (“Whole Model Test”) aparece la estadística c2 para el cociente de la ecuación (7):
que es el valor observado de la estadística de prueba. La probabilidad de obtener este valor (o uno mayor) suponiendo que todos los parámetros son cero es muy pequeña: 0.0006 por de lo que se deduce que los coeficientes β son estadísticamente distintos de cero y la respuesta (la elección del usuario) queda bien explicada por alguno de estos parámetros. La pseudo Rsquare que se muestra no es cercana a 1 (0.2847), sin embargo como ya se mencionó antes es difícil que en regresión logística se obtengan valores altos, lo cual no nos permite determinar si el ajuste resultó muy bueno o no, pero sí puede útil para comparar varios ajustes del mismo conjunto de datos (pudiera ser que al quitar parámetros no significativos del modelo éste tenga un mejor ajuste o no).
Figura 2. Corrida del modelo Logit en el paquete JMP Tocante a las proporciones de predicciones correctas, asignando el evento “Sí” a las probabilidades mayores a 0.5 con el modelo ajustado resulta indicando un ajuste razonable:
Finalmente en la última tabla del reporte generado por JMP v. 4.04, aparecen los valores estimados de los coeficientes β junto con los resultados de la pruebas de significancia individual de estos parámetros tanto al utilizar el cociente de verosimilitud como la estadística de Wald (ec. 8). El valor 0.0108 (menor a 0.05) asociado al parámetro β2 indica que éste es estadísticamente diferente de cero, implicando así que la diferencia de tiempo entre el uso de trasporte público y auto sí tiene influencia en la elección del usuario. Conclusiones El modelado de elección de alternativas ha mostrado ser La cuantificación de las elecciones de los individuos, Finalmente, cabe hacer notar que aunque se pueden ajustar datos en un modelo Logit “linealizando” la ecuación (3) con la llamada transformación Logit: Ln(P/(1 - P), la literatura del tema Bibliografía Ortúzar S., Juan de Dios.“Modelos econométricos de elección discreta”. Ediciones Universidad Católica de Chile. Pontificia Universidad Católica de Chile. Santiago, Chile. 2000. Ortúzar, J. de D. & Willumsen, L.G. “Modelling transport”. 2nd edition. John Wiley. UK. 1990. Ben-Akiva, M. & Lerman, S.R. “Discrete choice anayisis: Theory and application to travel demand”. The MIT Press. The Massachusetts Institute of Technology. USA. 1985. Greene, W.H. “Econometric analysis”. 4th edition. Prentice-Hall International, Inc. USA. 2000. Montgomery C. Douglas & Myers H. Raymond. “Generalized Linear Models”. Wiley-Interscience Publication.
Whitehead, J. “An Introduction to Logistic Regression. Evaluating the Performance of the Model”. Dept of Economics, Appalachian State University. [en línea]. Disponible en. http://personal.ecu.edu/whiteheadj/data/logit/pages/performance.htm. [Accesado en mayo/2005]. 2005 . Eric Moreno Quintero
Se agradecen los comentarios del Dr. Jorge Acha, de la Coordinación de Integración del Transporte.
|