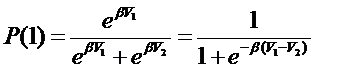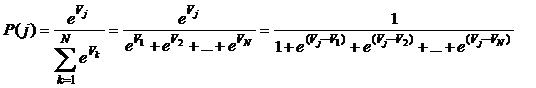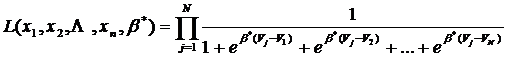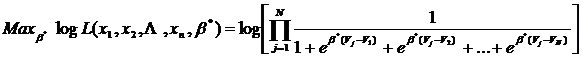|
|||||||||
Introducción En la planeación del transporte, tanto en pasajeros como en carga, la estimación de la demanda del servicio es un componente indispensable para anticipar acciones y medidas de control que mejoren el desempeño de los sistemas de transporte y disminuyan sus impactos no deseados. Por varios años, y aún en los años 1980, los pronósticos de demanda se basaron en métodos estadísticos sobre datos agregados de los usuarios del servicio. De las observaciones de las decisiones de los viajeros o de sus respuestas a cambios en tarifas, tiempos de recorrido, etc., los analistas explicaron los atributos del servicio que determinaban las decisiones de los viajeros usando métodos estadísticos clásicos como la regresión lineal múltiple. Este enfoque, basado en observaciones de las acciones de los usuarios se conoce en la literatura como de preferencias reveladas, y si bien fue un primer paso en la estimación de la demanda tuvo desventajas, como la necesidad de colectar enormes cantidades de datos, la dificultad de conocer características de las opciones de transporte no elegidas por los viajeros o la dificultad de estimar las reacciones de los usuarios a la introducción de servicios nuevos que nunca se habían ofrecido. A finales de los años 1970 y durante la década siguiente surgió un enfoque diferente, basado en técnicas de investigación de mercados para averiguar las preferencias de los usuarios del transporte; este enfoque se conoce como de preferencias declaradas, pues se basa en encuestas hechas a los viajeros en el sistema de transporte. Con esta perspectiva se resolvieron muchas de las limitaciones de las estimaciones agregadas que se tuvieron en el caso de las preferencias reveladas, y aunque al principio los pronósticos logrados no fueron muy buenos, ya en la década de los años 1990 la mejora en las técnicas estadísticas y en el diseño de cuestionarios mejoraron significativamente las estimaciones de demanda que se obtuvieron. La característica esencial de este enfoque es que se utilizan directamente los datos individuales de cada viajero. Este artículo muestra una síntesis de la publicación “Métodos de Elección Discreta en la Estimación de la Demanda de Transporte” que está por aparecer dentro de la serie de Publicaciones Técnicas del IMT. La intención es revisar las ideas básicas para familiarizarse con el tema de la estimación de la demanda con el enfoque de la maximización de la utilidad del viajero y el contexto probabilista de los modelos Logit, a fin de tener un documento que permita a los interesados en la aplicación de estas técnicas iniciarse en los detalles prácticos de su uso. El contexto metodológico La base teórica que sustenta el enfoque de preferencias declaradas es la modelación de elecciones discretas de los usuarios del transporte. Este tipo de modelos trata de reproducir el comportamiento de los viajeros que eligen frente a un número finito de opciones de viaje por algún motivo concreto (ir al trabajo, a la escuela, de compras, etc.), de manera que la demanda del sistema viene a ser el resultado de la suma de las elecciones individuales que hacen los viajeros. Cuando se logra construir un modelo de elecciones discretas que representa razonablemente el proceso de toma de decisiones de los viajeros, entonces los usuarios que el modelo pronostique para las distintas alternativas de viaje pueden sumarse para estimar el uso agregado de cada una de esas opciones. Los tres elementos básicos de un modelo de elecciones discretas son: 1. Identificar opciones de viaje disponibles y conocidas por el viajero que decidirá. 2. Identificar variables que influyen en la decisión de viajar, p. ej. el tiempo de viaje, la tarifa, el número de transbordos, etc., relacionadas con el viaje, y además variables socioeconómicas (sexo, edad, ingreso, etc.) que caractericen a los usuarios. 3. Un modelo matemático que represente las elecciones del usuario en función de las variables que afectan su decisión de viajar. Los dos primeros elementos se integran con relativa facilidad. El tercer elemento requiere de hipótesis apropiadas para representar la toma de decisiones de los viajeros. Lo primero que considera un modelo de elecciones del usuario, es que cuando éste elige una opción, manifiesta preferencia por esa opción. Así, por ejemplo, si un usuario va a trabajar en autobús en vez de usar su automóvil, muestra una preferencia por el transporte público. Las preferencias del usuario en sus elecciones ante un conjunto de alternativas dependen de los atributos de las opciones y de las características del propio usuario. Por ejemplo, atributos del viaje que influyen en la decisión del usuario pueden ser el tiempo del viaje, el costo o la confiabilidad de los itinerarios; mientras que las características del usuario que influyen en sus preferencias pueden ser: edad, sexo, ingreso o posesión de automóvil. Entonces, siendo la elección del usuario una muestra de sus preferencias, el modelo matemático se dirige hacia las preferencias de los viajeros ante las alternativas para viajar. El marco teórico adecuado para este fin es la Teoría de Utilidad, en el campo de la Economía, cuyo supuesto básico del comportamiento humano es que el valor de una decisión depende del bienestar que da o de la molestia que evita, que en términos económicos es la cantidad de utilidad generada por la decisión. Consecuencia de lo anterior es la hipótesis de que los usuarios del transporte siempre buscarán maximizar la utilidad derivada de las distintas alternativas que enfrentan al tomar una decisión. En el Capítulo 1 se resumen los antecedentes de los esfuerzos de modelación de la demanda de transporte a finales del siglo XX, y se presentan los enfoques de preferencias reveladas y preferencias declaradas que sustentan distintos métodos de estimación de demanda, así como las ideas fundamentales que se necesitan para desarrollar modelos de elección discreta, los cuales han mostrado su utilidad y su mayor alcance en términos de precisión de estimación en comparación con los métodos tradicionales utilizados en la década de los años 1980. El uso del concepto de utilidad y los modelos Logit En el Capítulo 2 se describen las ideas básicas para construir modelos de elección discreta. La sección 2.1 parte del principio de que los flujos de pasajeros en un sistema de transporte resultan de las elecciones de los viajeros, y que éstos siempre maximizan la utilidad que les da el viaje (o en su defecto siempre minimizan los inconvenientes). El principio de maximización de utilidad se vuelve operativo con la función de utilidad, una función matemática que representa las preferencias de los viajeros del sistema. El valor numérico de esta función depende de los atributos de la opción de viaje considerada y de las características del individuo que decide. La propiedad de la función de utilidad que representa las preferencias del usuario está en que si su valor numérico para una opción de viaje “a” es mayor que el correspondiente a la opción de viaje “b”, entonces el individuo preferirá la opción “a” sobre la “b”; y viceversa, si el individuo prefiere la opción de viaje “x” sobre otra “y”, entonces la función de utilidad tendrá un valor mayor evaluada en “x” que evaluada en “y”. Ante la presencia de un número finito de opciones, el individuo elegirá la más preferida, que es la que tiene el mayor valor de la función de utilidad. Los elementos de modelación de las preferencias con una función de utilidad son: a) el conjunto de alternativas disponibles A, con las opciones de viaje conocidas y disponibles para el usuario (automóvil, taxi, tren, etc.). Cada opción “j” del conjunto A tiene un conjunto de atributos Xj que la determinan (tiempo de viaje, costo, etc.). b) el conjunto de atributos S del individuo que elige y que son relevantes para la decisión como: edad, sexo, ingreso, núm. de automóviles poseídos, etc. Con el principio de maximización de utilidad, se busca una función U que depende tanto de los atributos de las alternativas del conjunto A como de los atributos S del individuo que decide, y tal que para cualquier par de alternativas j, k del conjunto A la relación: U(Xj , S) > U(Xk , S) indica que el usuario prefiere la opción j a la k y por tanto elegirá j si debe escoger entre ambas. Cuando se elige entre varias opciones de A, se elegirá la opción j siempre que se cumpla que: U(Xj , S) > U(Xk , S) para todas las opciones k en A. Para que la función de utilidad U(Xj , S) sea consistente, debe ser la misma para todas las opciones en A, con valores numéricos distintos para los distintos atributos Xj de las opciones en A; aunque puede haber coincidencia de valores para dos atributos Xj y Xk en cuyo caso habrá indiferencia en la elección de ambas opciones; además, para una alternativa j dada, el valor numérico de U(Xj , S) debe depender sólo de los atributos Xj y S de la propia alternativa y del individuo, y no depender de los atributos de otras alternativas en A. Con la función de utilidad se visualiza la dependencia entre las preferencias y las elecciones de los viajeros y los atributos tanto del viaje como de las características socioeconómicas de los usuarios, además de que permite pronosticar las reacciones de los usuarios ante cambios de los atributos en las opciones de viaje (cambios en tiempos de viaje, tarifas, etc.). Una función de utilidad para modelar las elecciones de los usuarios de un sistema de transporte no es única, Cualquier función matemática que represente numéricamente el orden de preferencias del viajero servirá como función de utilidad y dará las mismas predicciones de elección del usuario independientemente del valor numérico o del signo que resulten de su fórmula analítica. Con la información de las funciones de utilidad aplicadas a los individuos se pueden obtener resultados agregados para pronosticar el comportamiento colectivo de los usuarios de un sistema de transporte; los ejemplos numéricos en la Sección 2.1 ilustran algunos casos. Extendiendo el enfoque de modelación descrito con el principio de maximización de utilidad, en la Sección 2.1 se sigue con el enfoque probabilístico, el cual resuelve las contradicciones que se presentan con el uso de la función de utilidad cuando dos usuarios identificados con exactamente los mismos atributos de viaje, clasificados con las mismas características socioeconómicas y enfrentando una decisión ante un mismo conjunto de alternativas eligen de modo distinto. O también cuando un mismo individuo enfrentado en ocasiones distintas a las mismas opciones de viaje elige diferente en cada ocasión. Luego de revisar algunas razones por las que los viajeros muestran variaciones que parecen contradictorias en sus elecciones, se discute la idea de utilidad aleatoria, que extiende el concepto de función de utilidad sumando un término de error para representar todos los factores no conocidos por el analista y que influyen en la decisión del viajero. Ya con este concepto de utilidad aleatorio se prosigue en la Sección 2.2 con los modelos Logit, que son la versión probabilista de modelos de elección discreta más difundida en la literatura, y la que ha tenido más aplicaciones prácticas. Comenzando con el modelo Logit binomial, para la elección entre dos alternativas “1” y “2”, se revisa el modelo de elección que resulta ser una densidad logística donde la probabilidad de elegir la opción “1” es:
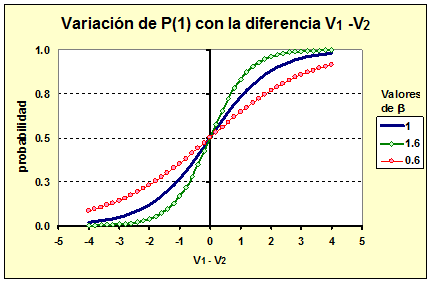
La curva de esta densidad tiene la forma de una “S” alargada y mapea el dominio de la variable (V1 – V2) que es la diferencia de utilidades entre la opción “1” y la opción “2”, sobre el intervalo [0, 1] que representa la probabilidad medida. Dependiendo del valor del parámetro b se obtienen distintas curvas como se ve en la siguiente gráfica.
En estas gráficas se ve que cuando V1 - V2 = 0, indicando que la utilidad de ambas alternativas es la misma, la probabilidad de elegir la alternativa 1 es 0.5, que corresponde a la situación de indiferencia frente a la alternativa 2. A medida que V1 - V2 toma valores positivos cada vez mayores, indicando que la utilidad de la alternativa 1 es cada vez mayor comparada a la de la alternativa 2, la probabilidad de elegir la alternativa 1 aumenta tendiendo a uno; y viceversa, cuando la diferencia V1 - V2 toma valores negativos indicando que la alternativa 2 tiene mejor utilidad que la 1, la probabilidad de elegir la alternativa 1 disminuye, aproximándose a cero. Este es el comportamiento esperado de un modelo de elecciones discretas, y es consistente con el principio de maximización de utilidad. Prosiguiendo con el modelo Logit, se revisa luego el caso multinomial, en el cual hay N alternativas, con utilidades sistemáticas V1, V2,…, VN, y en el cual la probabilidad de elegir la alternativa “j” es:
Con este modelo Logit multinomial la sección 2.2 continúa con varios ejemplos numéricos de cálculo de probabilidades, de estimaciones agregadas de reparto porcentual de usuarios entre las alternativas y de pronóstico de cambios en estos porcentajes ante cambios en los atributos del viaje como son el aumento en el costo de combustibles. Otro ejemplo mostrado es el caso de la introducción de una alternativa nueva, que es una de las ventajas que tienen estos modelos Logit, ya que permiten pronosticar comportamientos de usuarios en circunstancias donde no se tienen datos históricos debido a la novedad de dicha alternativa. La sección 2.2 concluye revisando la introducción de constantes específicas para alternativas, que se usan para refinar el modelo de elección añadiendo constantes que determinen mejor la influencia de alguna alternativa particular, como es el caso en el que se compara la elección entre automóvil particular y transporte público considerando a los individuos que poseen automóvil y a los que no lo tienen. También se revisa una propiedad importante de los modelos Logit, que es la independencia de las alternativas irrelevantes, que fue descrita por Luce y Suppes (1965) como sigue: “Siempre que dos alternativas tengan probabilidades positivas de ser elegidas, la razón de una probabilidad a la otra permanece inalterada por la presencia o ausencia de cualquier otra alternativa adicional en el conjunto de opciones disponibles”. El capítulo 2 continúa con la Sección 2.3 que trata del desarrollo de las variables que se utilizan en los modelos Logit; la conveniencia de desagregar los tiempos de viaje en el tiempo que el usuario viaja más los tiempos de acceso a paradas o terminales más los tiempos de espera. Esta sección muestra algunos ejemplos numéricos ilustrativos. Finalmente, el capítulo concluye con la Sección 2.4 en la que se discuten los detalles prácticos para determinar el conjunto de alternativas que se puede utilizar en la modelación y muestra ejemplos numéricos de diversos cálculos con distintos conjuntos de opciones. La estimación de los parámetros En el Capítulo 3, la Sección 3.1 aborda la cuestión de la estimación de los parámetros, comenzando con una discusión sobre el contexto estadístico del modelo y la necesidad de cambiar a un enfoque distinto al usado en la típica regresión lineal por mínimos cuadrados. Luego de esta discusión en la Sección 3.2 se analiza el proceso de estimación usado en los modelos Logit, que es el método de máxima verosimilitud, en el cual se maximiza la función de densidad conjunta dependiente de los parámetros b1, b2,…, bj de un modelo Logit multinomial, en la cual se introducen los datos de la muestra obtenida de la población de usuarios para hacer el ajuste. Se define la función de verosimilitud L de los atributos xk de la muestra en función de los parámetros b*:
Y se plantea el proceso de estimación como un problema de maximización no lineal que da como resultado los parámetros b* que ajustan el modelo Logit:
Se muestran algunos ejemplos numéricos de ajuste de parámetros en los cuales se utiliza el módulo Solver de Excel para resolver el problema de optimización no lineal planteado en un modelo Logit binomial y en uno que incluye una constante específica de un reparto modal entre automóvil y autobús. Continuando en la Sección 3.3 los resultados se comparan con los que da el módulo de regresión logística del paquete estadístico JMP v.9.0, en el cual se obtienen además criterios de bondad de ajuste estadística, como es la estadística de Wald y el porcentaje de aciertos entre elecciones pronosticadas contra elecciones observadas en la muestra. Se discute también la significancia de los parámetros b* estimados en el modelo y se dan criterios básicos para decidir la inclusión o exclusión de las variables en el modelo en atención al nivel de significación de sus parámetros estimados. La sección 3.3 concluye con una serie de recomendaciones prácticas en la estimación de los parámetros del modelo a fin de evitar errores comunes en la construcción del mismo, como es el caso de tener demasiadas constantes específicas de alternativas; la especificación inadecuada de las variables socioeconómicas que describen a los usuarios o el problema de la colinealidad perfecta entre variables incluidas en el modelo. Aplicaciones y conclusión En el capítulo 4 se muestran algunas aplicaciones de los modelos de elección discreta. La sección 4.1 trata la cuestión de aplicar estos modelos al problema de elegir ruta en un sistema de transporte y al problema de elegir la hora de partida para un viaje. En cada caso se mencionan los aspectos esenciales que se deben considerar para modelar adecuadamente estos problemas de elección discreta y se sugieren factores convenientes para incluir en el proceso de modelado. La sección 4.2 continúa con la revisión de los métodos para producir pronósticos agregados a partir de la información de elecciones discretas que proporcionan los modelos Logit. Estos pronósticos agregados son de gran interés para los analistas y modeladores del transporte, pues proporcionan las estimaciones básicas para propósitos de planeación de los sistemas de transporte. En esta sección se muestran algunos ejemplos numéricos de estimaciones agregadas con base en información de las elecciones individuales de los viajeros. Es con estas estimaciones de las decisiones agregadas que se pueden prever el uso de los sistemas; sus dimensiones; su mejora; y en casos de servicios nuevos, la utilización potencial de los servicios y la magnitud esperada de recursos necesarios para operar eficientemente los servicios de transporte ofrecidos. La sección 4.2 concluye con un resumen breve de métodos de pronóstico agregado con base en información de los modelos de elección discreta, recomendaciones de su uso según el caso que se tenga de disponibilidad de datos y algunos ejemplos numéricos ilustrativos. Finalmente, en el Capítulo 5 se resumen los puntos principales de la revisión que se hace en esta investigación y se dan sugerencias para trabajos futuros que continúen el tema con aspectos más avanzados. Bibliografía Amos WEB GLOSS*arama, (2010) Utilitarianism; Utility maximization. En: http://www.AmosWEB.com. AmosWEB LLC, 2000-2010. Ben-Akiva, M. & Lerman, S.R. (1985). Discrete choice anayisis: Theory and application to travel demand. The MIT Press. The Massachusetts Institute of Technology. USA. Ben-Akiva, M. and Bierlaire, M. (2003). Discrete Choice Models with Applications to Departure Time and Route Choice. In: Handbook of Transportation Science. Edited by Randolph W. Hall. Kluwer Academic Press. USA. Greene, W.H. (2000). Econometric analysis. 4th edition. Prentice-Hall International, Inc. USA. Hensher, D.A., Rose, J.M., and Greene, W.H. (2007). Applied choice analysis. A primer. 3rd printing. Cambridge University Press. New York. Horowitz, J.L., Koppelman, F.S. and Lerman, S.R. (1986). A Self-Instructing Course in Disaggregate Mode Choice Modeling. Federal Transit Administration, U.S. Department of Transportation. Washington. Kanafani, A. (1983). Transportation Demand Analysis. McGraw-Hill. USA. Kreyszig, E. (1970). Introductory Mathematical Statistics. Principles and Methods. John Wiley & Sons. New York. Luce, R.D. and Suppes, P. (1965). Preference, utility and subjective probability. EN: R.D. Luce, R.R. Bush and E. Galanter, editors, Handbook of Mathematical Psychology. John Wiley & Sons, New York. Montgomery C. Douglas & Myers H. Raymond (2002). Generalized Linear Models. Wiley-Interscience Publication Nelson, D. (2004). The Penguin Dictionary of Statistics. Penguin Books. London. Ortúzar, J.D, and Willumsen, L.G. (1994). Modelling transport. Second edition. John Wiley & Sons. Chichester, UK. Ortúzar, J.D. (2000). Modelos de demanda de transporte. 2ª. Edición. Ediciones Universidad Católica de Chile. Alfaomega Grupo Editor S.A. México. Train, K.E. (2009). Discrete Choice Methods with Simulation. 2nd edition. Cambridge University Press. New York. MORENO Eric |